
A data-driven world demands precision to achieve massive gains for organizational success. The reliability and accuracy of the machine learning model mean the world to businesses, which depend heavily on them to guide future decisions. Marking the way ahead is concept drift and data drift; that needs an in-depth comprehension as you stride into the future.

Gartner further projects that 65% of B2B sales organizations will transition from intuition-based to data-driven approaches by 2026. Understanding the depletion of data models over time can help understand decision-making better. Let us dive deeper into the data model depletion and understand the concept and data drift in detail.
Understanding Data Model Depletion
Data model depletion is the process of physically removing data from a data model or database, often to reflect a change in the real-world entity or to improve data integrity. It involves strategically removing or marking as unavailable data that is no longer relevant or accurate. Data model depletion is a crucial part of data management and is deployed across contexts such as resource management, database management, data warehousing, and scientific modeling. Depletion drastically improves data integrity, reduces storage requirements, enhances query performance, and simplifies data analysis.
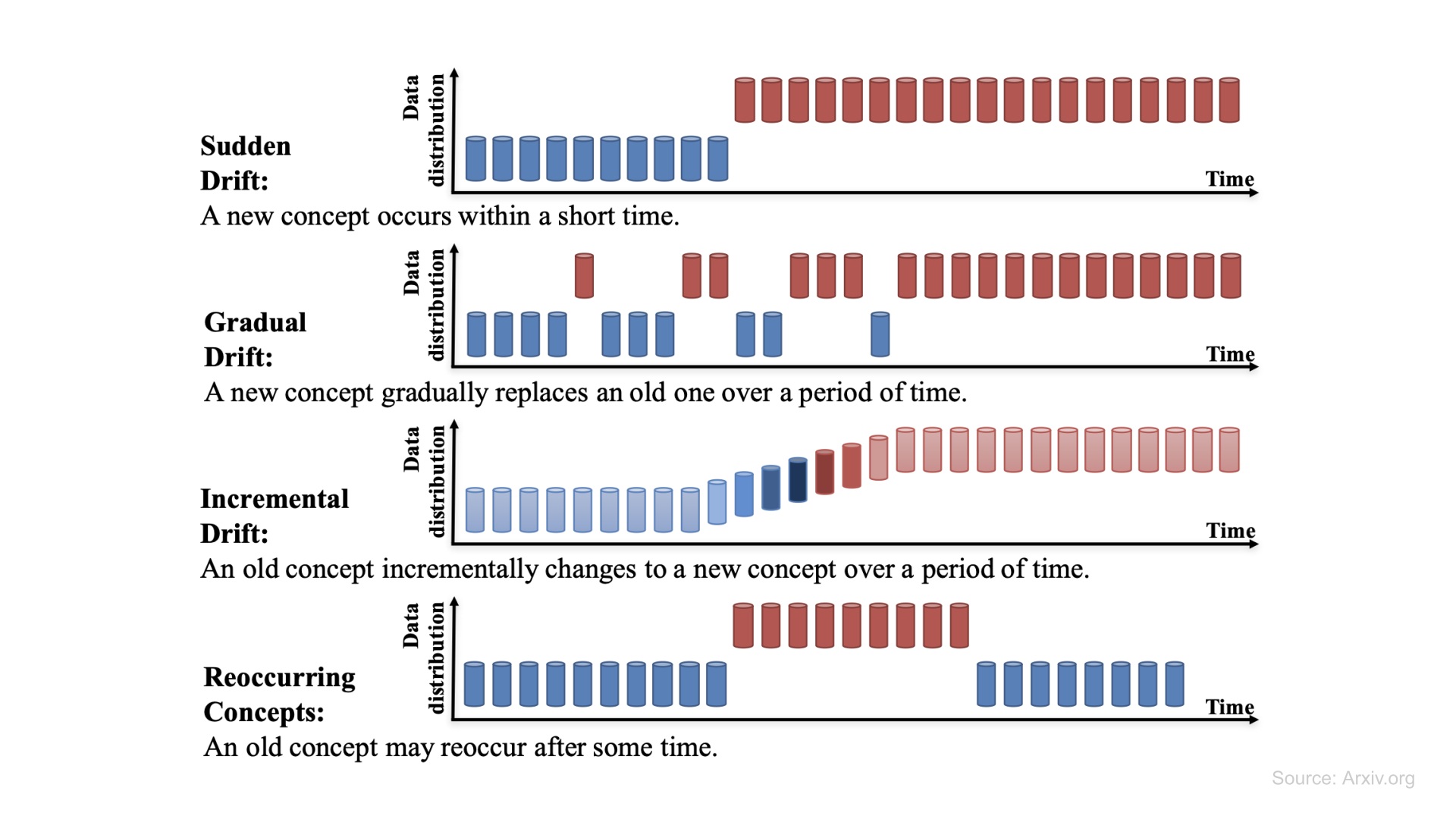
Concept Drift
Meaning: Concept drift in machine learning is a situation where the statistical relations between input data and target values change over time. This infers that the model’s assumptions about the data zero down to being invalid, leading to a diminished prediction accuracy. Examples include fraud detection, spam filtering, etc.
Concept Drift can be further divided into four categories:
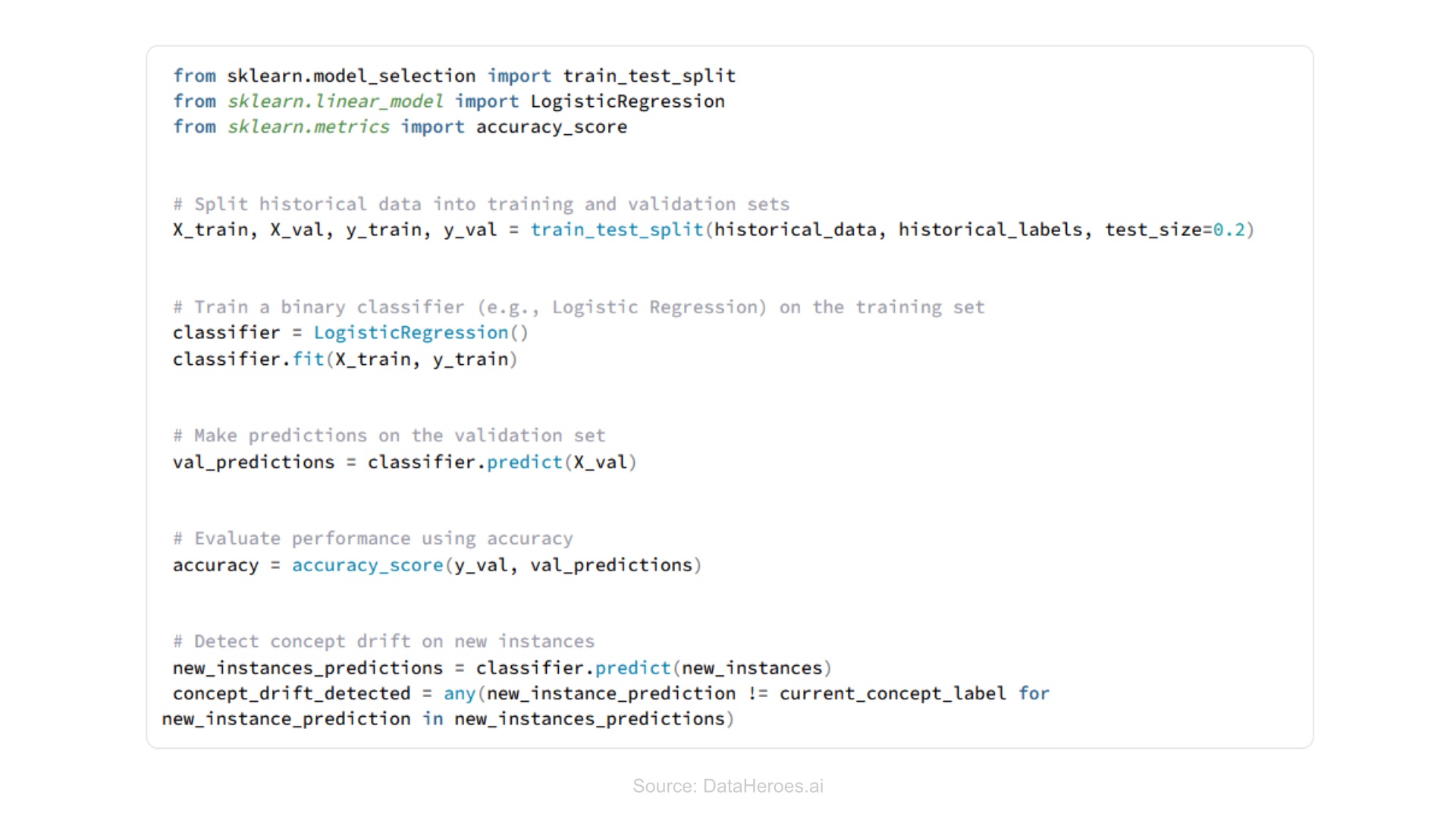
Supervised Learning
Unsupervised Learning

It involves leveraging the inherent patterns and structures within the data to identify changes indicative of concept drift without relying on labeled data.
Ensemble methods
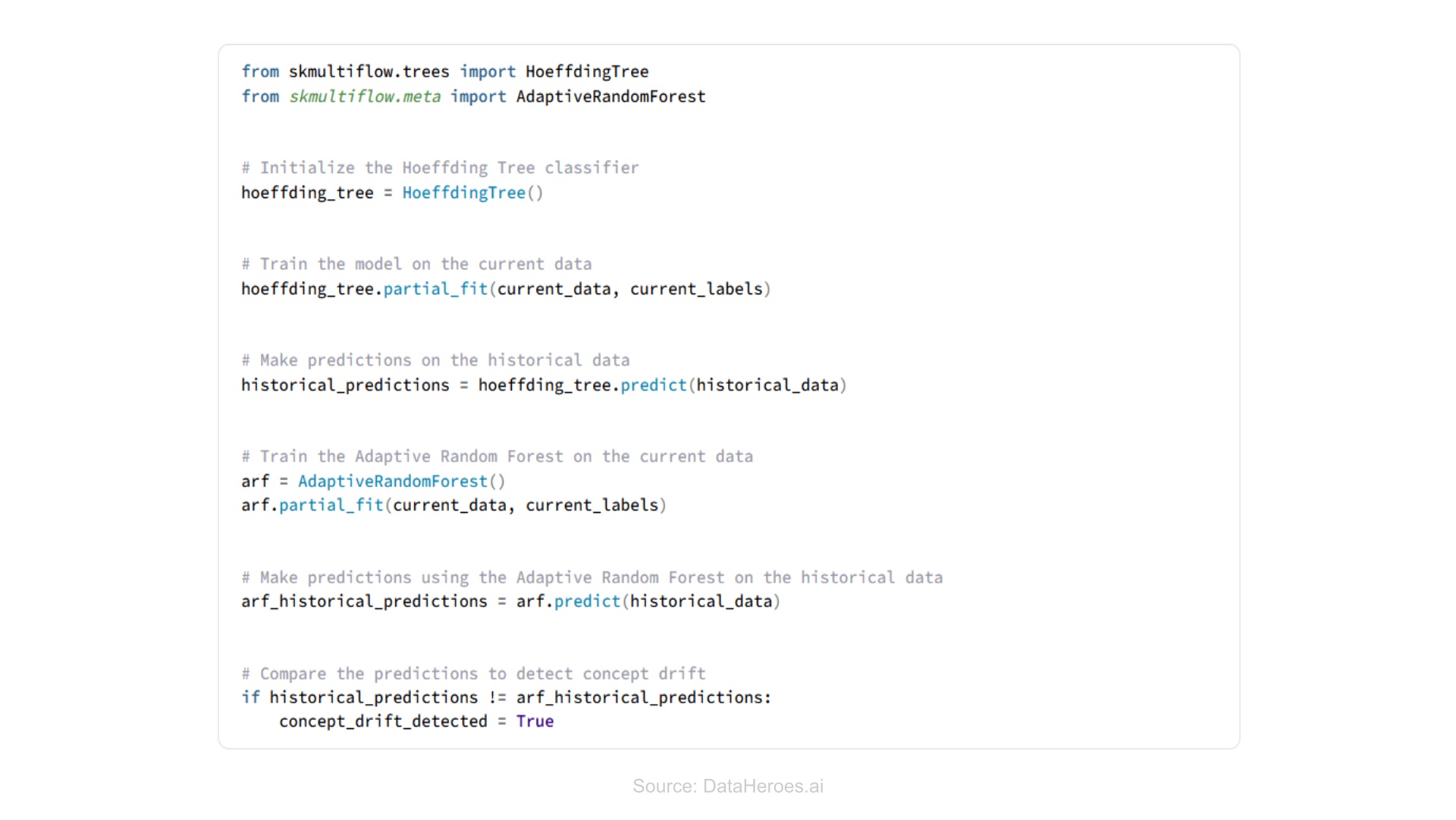
It trains multiple models and uses multiple classifiers to detect concept drift.
Data Drift
Statistical measures
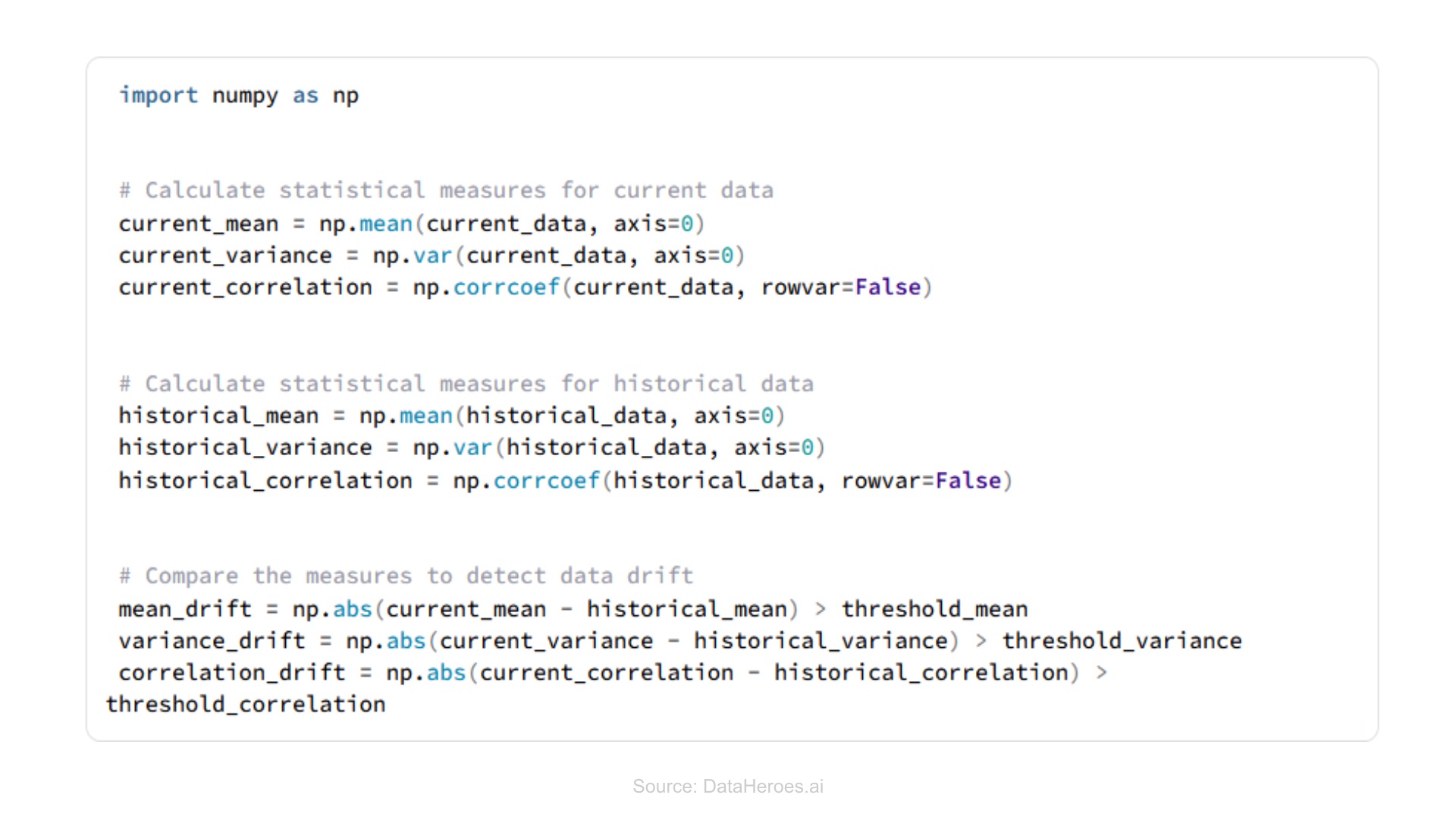
It involves comparing statistical measures of the current data distribution with the historical distribution used for training.
Hypothesis testing
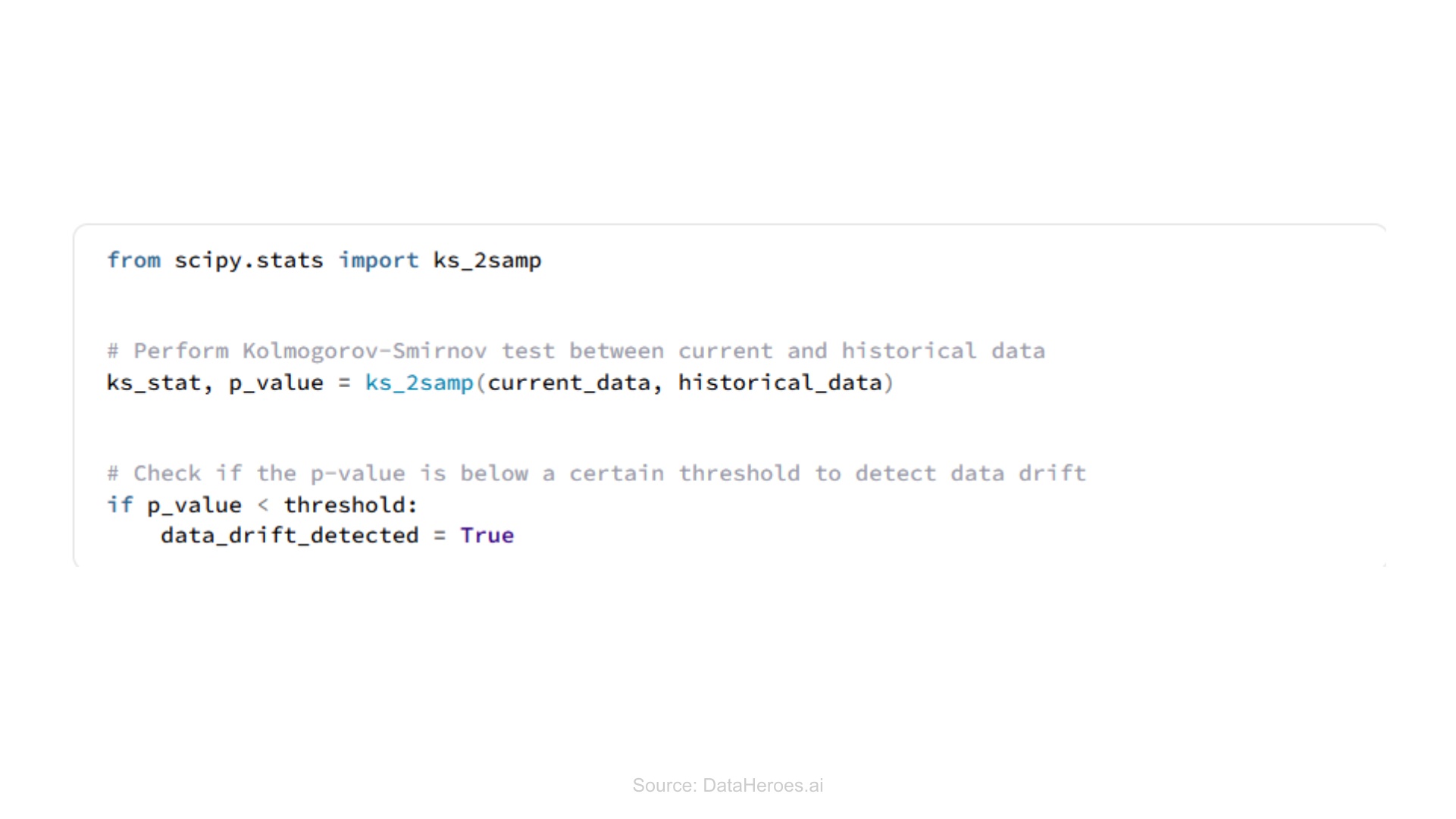
It determines if there is a significant difference between current and historical data; or otherwise.
Machine learning drift detectors
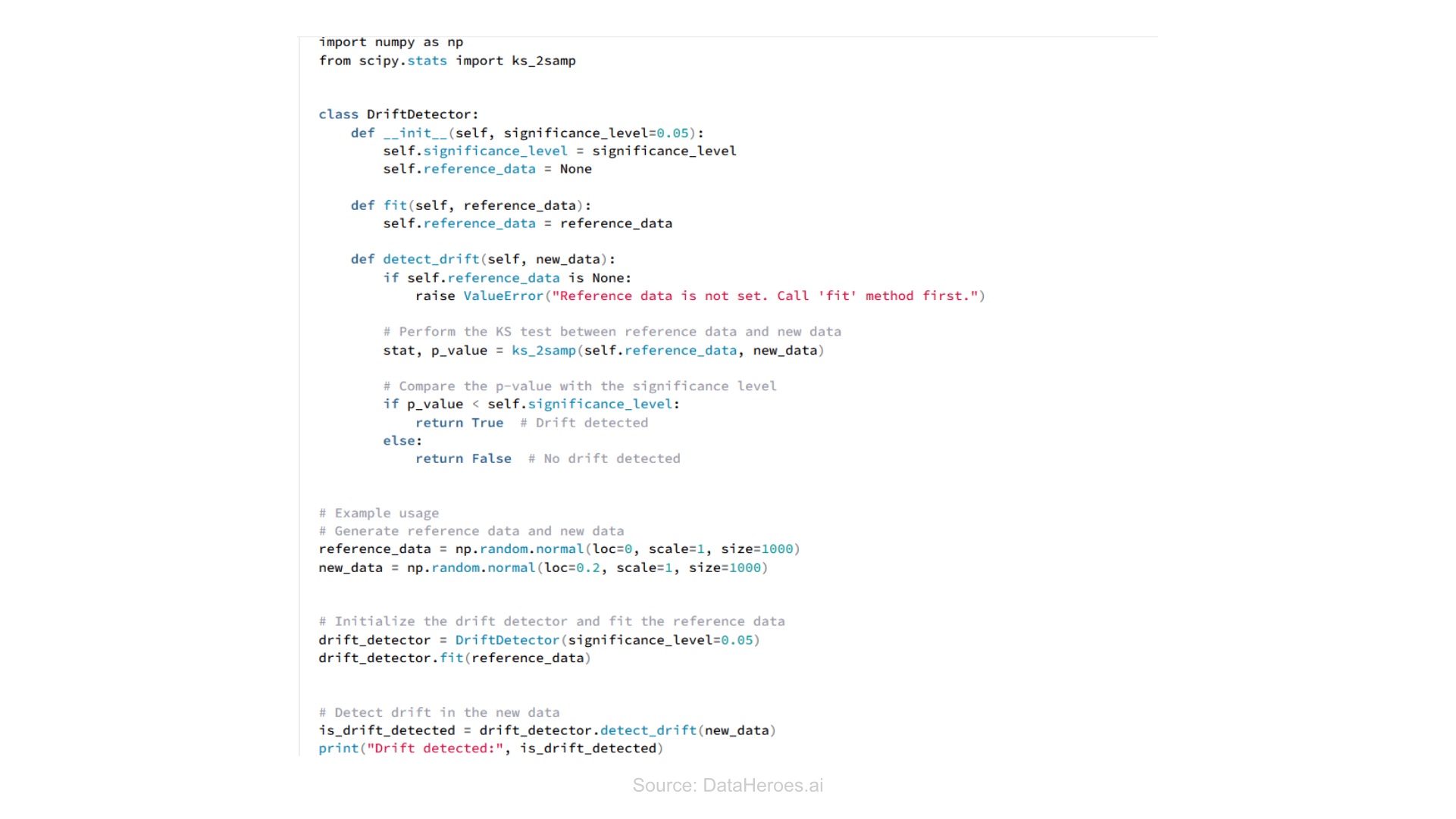
These are specialized algorithms designed to detect data drift using machine learning techniques. These help in analyzing the differences in model predictions or feature distribution between the current and historical data.
Ways to Overcome These Discrepancies:
Performance monitoring, data and concept drift detection algorithms, data, and concept drift prevention techniques, and retraining and fine-tuning. By regularly monitoring for model drift and taking proactive steps to prevent or mitigate it, it is possible to maintain the accuracy and reliability of machine learning models over time. Both data drift and model drift can lead to inaccuracy or ineffective decisions; maintain the performance of a machine learning model over time.
This website uses cookies to enhance website functionalities and improve your online experience. By clicking Accept or continue browsing this website, you agree to our use of cookies as outlined in our privacy policy.